ghci 的基础命令
:q退出:l加载命令:t检查实际的类型:info查看类型信息
编译命令:ghc hello.hs -o testprogram
函数
最简单的函数
simple x = x
lambda
匿名函数
ghci> (\x -> x) 5
5
可以用 where 获得更清晰的表达:
sumSquareOrSquareSum x y = if sumSquare > squareSum
then sumSquare
else squareSum
where sumSquare = x^2 + y^2
squareSum = (x + y)^2
Haskell 有另一种 where 子句的替代方案,称为 let 表达式,可以用 let 重写:
sumSquareOrSquareSum x y = let sumSquare = (x^2 + y^2)
squareSum = (x + y)^2
in
if sumSquare > squareSum
then sumSquare
else squareSum
在大多数情况下,选择使用 let 还是 where,只是风格问题。
作用域:
x = 4
add1 y = y + x
add2 y = (\x -> y + x) 3
add3 y = (\y -> (\x -> y + x) 1 ) 2
创建函数的时候,实际上就创建了一个作用域,保存了当时的上下文。当变量被使用的时候,程序会寻找最近的作用域。
ghci> add1 1
5
ghci> add2 1
4
ghci> add3 1
3
函数是一等公民
函数在 Haskell 中是一等公民(first-class)。函数可以作为函数参数传入,也可以作为函数返回值。
ifEven myFunction x = if even x
then myFunction x
else x
将函数作为参数最典型的例子就是自定义排序。
List
ghci> :t [1,2,3]
[1,2,3] :: Num a => [a]
ghci> :t reverse
reverse :: [a] -> [a]
ghci> reverse [1,2,3]
[3,2,1]
ghci> [1,2,3] ++ [4,5,6]
[1,2,3,4,5,6]
ghci> head [1,2,3]
1
ghci> tail [1,2,3]
[2,3]
ghci> length [1,2,3]
3
还能直接生成值:
ghci> [1 .. 10]
[1,2,3,4,5,6,7,8,9,10]
ghci> [1,3.. 10]
[1,3,5,7,9]
获取特定下标的元素使用的 !!:
ghci> [1,2,3] !! 1
2
当然,也可以用函数的写法:
ghci> (!!) [1,2,3] 1
2
检查值是否在列表中 elem:
ghci> elem 3 [1,2,3]
True
ghci> 3 `elem` [1,2,3]
True
take 可以取前 n 个元素:
ghci> take 5 [2,4..100]
[2,4,6,8,10]
drop 则移除前 n 个元素:
ghci> drop 2 [1,2,3,4,5]
[3,4,5]
zip 可以将两个列表合并成元组(tuple)列表。(Python 也有一样的方法)
ghci> zip [1,2,3][2,4,6]
[(1,2),(2,4),(3,6)]
cycle 特别有意思,它可以无限重复列表(基于惰性计算)。听起来好像没什么用,但是在数值计算中经常需要一个包含 n 个 1 的列表,就可以使用这个方法:
ghci> ones n = take n (cycle [1])
ghci> ones 2
[1,1]
ghci> ones 4
[1,1,1,1]
还有比如说在进行分组的时候其实特别有用:
assignToGroups n aList = zip groups aList
where groups = cycle [1..n]
ghci> assignToGroups 3 ["file1.txt","file2.txt","file3.txt","file4.txt","file5.txt","file6.txt","file7.txt","file8.txt"]
[(1,"file1.txt"),(2,"file2.txt"),(3,"file3.txt"),(1,"file4.txt"),(2,"file5.txt"),(3,"file6.txt"),(1,"file7.txt"),(2,"file8.txt")]
递归和模式匹配
递归实现一个欧几里得算法(最大公约数):
myGCD a b = if remainder == 0
then b
else myGCD b remainder
where remainder = a `mod` b
可以看到 Haskell 写算法的优雅了吧!几乎就是欧几里得算法的直接表达:
求 a 和 b 的最大公约数,如果余数为 0,那么就是 b,否则最大公约数就是 b 与 余数的最大公约数。
除了用 if 来作为递归基,还可以考虑用模式规则(和 C++ 模板类似):
fib 0 = 0
fib 1 = 1
fib n = fib (n-1) + fib (n -2)
高阶函数
map
map 基本已经成为现在语言的标配了,它可以对整个列表内的元素进行映射,从而获得新的值。
ghci> map reverse ["dog", "cat", "moose"]
["god","tac","esoom"]
ghci> map (^2) [1,2,3]
[1,4,9]
filter
filter 跟 map 类似,只不过它传入的函数需要返回 True 或者 False,然后会筛选出符合条件的值。
ghci> filter even [1,2,3,4]
[2,4]
ghci> filter (\(x:xs) -> x == 'a') ["apple","banana","avocado"]
["apple","avocado"]
folding
foldl (l 是左边(left)的意思)可以将一个列表归纳成一个值。函数参数有三个,一个二元函数,一个初始值和一个列表。
ghci> foldl (+) 0 [1,2,3,4]
10
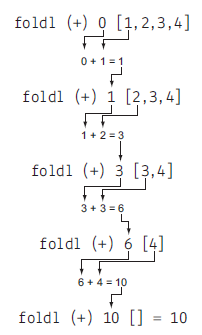
可以用它实现连接列表中的字符串:
ghci> concatAll xs = foldl (++) "" xs
ghci> concatAll ["This", " ", "is", " ", "an", " ", "apple."]
"This is an apple."
foldl 的 l 是左边,自然就有 flodr,其中,r 是右边(right)。
ghci> foldr (-) 0 [1,2,3,4]
-2
ghci> foldl (-) 0 [1,2,3,4]
-10
类型
Haskell 是一个静态类型语言。
x::Int
x = 2
ghci> x^2
4
ghci> x*2000
4000
ghci> x^2000
0
Int 和其它的编程语言的 int 类似,范围是有限制的。Integer 则更接近于数学意义上的整数:
x::Integer
x = 2
ghci> x^2000
114813069527425452423283320117768198402231770208869520047764273682576626139237031385665948631650626991844596463898746277344711896086305533142593135616665318539129989145312280000688779148240044871428926990063486244781615463646388363947317026040466353970904996558162398808944629605623311649536164221970332681344168908984458505602379484807914058900934776500429002716706625830522008132236281291761267883317206598995396418127021779858404042159853183251540889433902091920554957783589672039160081957216630582755380425583726015528348786419432054508915275783882625175435528800822842770817965453762184851149029376
Haskell 提供一些其它语言中类似的类型:
letter :: Char
letter = 'a'
interestRate :: Double
interestRate = 0.375
isFun :: Bool
isFun = True
values :: [Int]
values = [1,2,3]
testScores :: [Double]
testScores = [0.99, 0.7, 0.8]
letters :: [Char]
letters = ['a', 'b', 'c']
函数同样也是有类型的,-> 用于划分参数和返回值:
double :: Int -> Int
double n = n*2
类型转换:
half :: Int -> Double
half n = (fromIntegral n) / 2
不能直接使用 n / 2,Haskell 不会做隐式的类型转换。另一方面,Haskell 的类型更加灵活,Haskell 的数字字面量的类型是 多态的(polymorphic),由编译器根据使用的情况决定。
多个函数参数的类型
makeAddress :: Int -> String -> String -> (Int, String, String)
makeAddress number street town = (number, street, town)
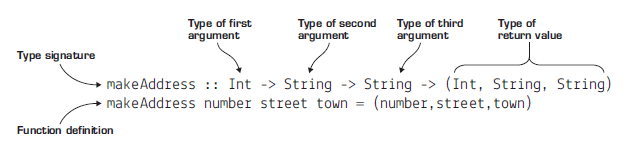
可以发现似乎参数和返回值有点奇怪。其实是因为多个函数参数可以理解成嵌套的 Lambda 函数:
makeAddressLambda :: Int -> String -> String -> (Int, String, String)
makeAddressLambda = \number -> \street -> \town -> (number, street, town)
这种将接受多个参数的函数转换为一系列只接受单个参数的函数的技术被称为 柯里化(Currying)。在 Haskell 中,所有函数都是自动柯里化的。
创建新的类型
参数别名,例如 [Char] 被重命名为 String。虽然二者实质是一样的,但通过类型别名,可以获得更富有含义的指代,特别是在实际代码中,这样代码的可读性会更高。
type Age = Int
重建新的类型可以使用 data:
data Sex = Male | Female
通过建立类型,可以获得更好的抽象能力:
type FirstName = String
type LastName = String
type MiddleName = String
data Name = Name FirstName LastName | NameWithMiddle FirstName MiddleName LastName
showName :: Name -> String
showName (Name f l) = f ++ " " ++ l
showName (NameWithMiddle f m l) = f ++ " " ++ m ++ " " ++ l
虽然本质上就是字符串,但通过类型别名和重建 Name,代码获得了更高的可读性,同时也给编译器提供了足够的类型信息用于检查 bugs。
ghci> name1 = Name "Jerome" "Salinger"
ghci> name2 = NameWithMiddle "Jerome" "David" "Salinger"
ghci> showName name1
"Jerome Salinger"
ghci> showName name2
"Jerome David Salinger"
用过类型包含的字段比较多,可以使用 record 语法:
data Patient = Patient {name :: Name, sex :: Sex, age :: Int, weight :: Int, height :: Int}
jackieSmith :: Patient
jackieSmith = Patient {name = Name "Jackie" "Smith", age = 43, sex = Female, height = 62, weight = 115}
可以看到,这个语法对于类型字段比较的时候可读性会更高。
ghci> height jackieSmith
62
ghci> age jackieSmith
43
如果需要更新某个字段的值,也只需要传入需要更新的对应字段:
jackieSmithUpdated = jackieSmith { age = 32 }
需要注意,这是个 纯函数 的世界,这里会创建一个新的类型值,所以必须绑定到一个新的变量上。
类型类
类型类(type classes)可以让你基于类的 共同行为 对类型进行分类。这和其它语言中的接口很类似。
ghci> :info Num
type Num :: * -> Constraint
class Num a where
(+) :: a -> a -> a
(-) :: a -> a -> a
(*) :: a -> a -> a
negate :: a -> a
abs :: a -> a
signum :: a -> a
fromInteger :: Integer -> a
{-# MINIMAL (+), (*), abs, signum, fromInteger, (negate | (-)) #-}
-- Defined in ‘GHC.Num’
instance Num Word -- Defined in ‘GHC.Num’
instance Num Integer -- Defined in ‘GHC.Num’
instance Num Int -- Defined in ‘GHC.Num’
instance Num Float -- Defined in ‘GHC.Float’
instance Num Double -- Defined in ‘GHC.Float’
使用 Num 作为函数的参数,那么只要满足 Num 定义的类都可以传入(可以看到 Go 语言的接口借鉴了这种实现):
addThenDouble :: (Num a) => a -> a -> a
addThenDouble x y = (x + y) * 2
使用 Num 这个类型类后,代码支持的类型就不仅仅只是 Int 和 Double 了,也包括所有实现了 Num 的类,无论是内置的还是第三方开发者写的。
定义类型类
可以通过 where 定义类需要拥有的方法,例如我们可以设计一个 describe 方法,用来描述类型,那么就可以使用:
class Describable a where
describe :: a -> String
通用的基础类型类
比如在排序算法中,我们必须要有一个方法对两个值进行比较才可以排序。像 C++ 中,我们可能会重载 < 符号,实现自定义的排序。这些我们可以理解成类型的基础能力。例如 数字 是可以比较大小的,描述支持比较,用的就是 Ord 和 Eq:
class Eq a where
(==) :: a -> a -> Bool
(/=) :: a -> a -> Bool
class Eq a => Ord a where
compare :: a -> a -> Ordering
(<) :: a -> a -> Bool
(<=) :: a -> a -> Bool
(>) :: a -> a -> Bool
(>=) :: a -> a -> Bool
max :: a -> a -> a
min :: a -> a -> a
ghci> :t (>)
(>) :: Ord a => a -> a -> Bool
不难从逻辑上发现实现 Ord 必须实现 Eq,我们需要知道两者是否相等才可以进一步说其中一个值是否比另一个大。然而,实现 Eq 却未必可以比较。比如你可以判断香草冰淇淋和巧克力的异同 Eq,却无法将它两者进行直接比较 Ord。
如果通过 :info 比较 Int 和 Integer 这两个类型的区别,就会发现 Int 实现了 Bounded,而 Integer 没有实现 Bounded。
class Bounded a where
minBound :: a
maxBound :: a
ghci> minBound ::Int
-9223372036854775808
ghci> maxBound ::Int
9223372036854775807
注意,minBound 和 maxBound 是值而不是函数。
常用的类型类还有 Show:
ghci> :info Show
type Show :: * -> Constraint
class Show a where
showsPrec :: Int -> a -> ShowS
show :: a -> String
showList :: [a] -> ShowS
任意的类型只要实现了 show 就可以被打印,类似 Java 的 toString。
对于一些常规的类型类是可以直接派生(deriving)的,比如:
data IceCream = Chocolate | Vailla
ghci> Chocolate
<interactive>:14:1: error:
• No instance for (Show IceCream) arising from a use of ‘print’
• In a stmt of an interactive GHCi command: print it
data IceCream = Chocolate | Vailla deriving (Show)
ghci> Chocolate
Chocolate
可以看到加上 deriving (Show),就可以实现了打印了。不仅仅是打印,还可以派生自 Eq 和 Ord:
data IceCream = Chocolate | Vailla deriving (Show, Eq, Ord)
ghci> Chocolate == Vailla
False
ghci> Chocolate /= Vailla
True
实现类型类
考虑一个六面的骰子,
data SixSidedDie = S1 | S2 | S3 | S4 | S5 | S6
非常重要一个类型是 Show,这样我们就可以打印了,那么最简单的方式自然就是 deriving (Show):
data SixSidedDie = S1 | S2 | S3 | S4 | S5 | S6 deriving (Show)
ghci> S1
S1
ghci> S2
S2
如果想改变这种显示,就需要实现 Show:
data SixSidedDie = S1 | S2 | S3 | S4 | S5 | S6
instance Show SixSidedDie where
show S1 = "one"
show S2 = "two"
show S3 = "three"
show S4 = "four"
show S5 = "five"
show S6 = "six"
ghci> S1
one
ghci> S2
two
大多时候直接使用 deriving 就可以了,不需要自己去实现。例如:Ord 实现起来就很麻烦,即使用模式匹配也要对每一面定义比较操作。
instance Enum SixSidedDie where
toEnum 0 = S1
toEnum 1 = S2
toEnum 2 = S3
toEnum 3 = S4
toEnum 4 = S5
toEnum 5 = S6
toEnum _ = error "No such value"
fromEnum S1 = 0
fromEnum S2 = 1
fromEnum S3 = 2
fromEnum S4 = 3
fromEnum S5 = 4
fromEnum S6 = 5
ghci> [S1 .. S6]
[one,two,three,four,five,six]
ghci> [S1 .. ]
[one,two,three,four,five,six,*** Exception: No such value
CallStack (from HasCallStack):
error, called at hello.hs:102:14 in main:Main
但是,我们其实只需要 deriving (Enum):
data SixSidedDie = S1 | S2 | S3 | S4 | S5 | S6 deriving (Enum)
ghci> [S1 .. ]
[one,two,three,four,five,six]